| Tel:400-889-7783 | 中文 |English |
|
NVIDIA
|
|
AI INFERENCE
To connect us with the most relevant information, services, and products, hyperscale companies have started to tap into AI. However, keeping up with user demand is a daunting challenge. For example, the world’s largest hyperscale company recently estimated that they would need to double their data center capacity if every user spent just three minutes a day using their speech recognition service.
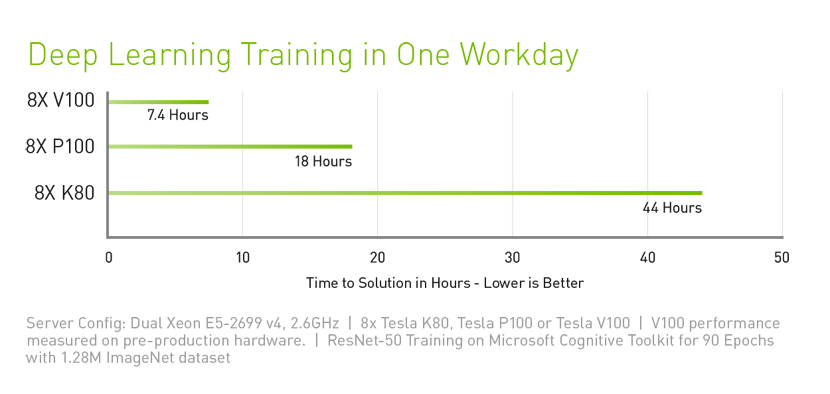
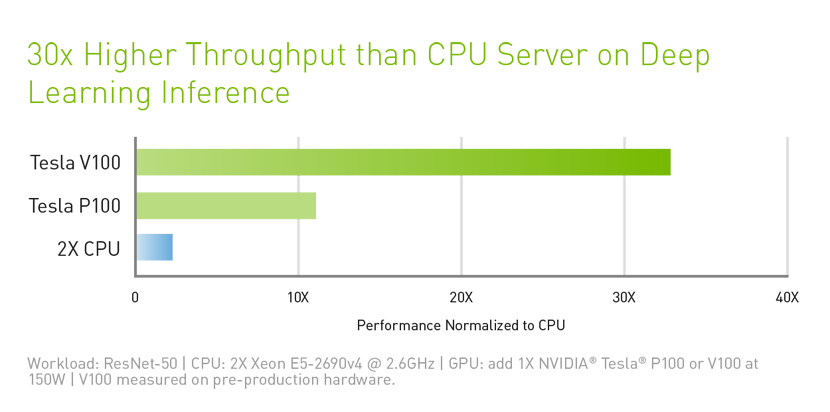
Tesla V100 is engineered to provide maximum performance in existing hyperscale server racks. With AI at its core, Tesla V100 GPU delivers 30X higher inference performance than a CPU server. This giant leap in throughput and efficiency will make the scale-out of AI services practical.
HIGH PERFORMANCE COMPUTING (HPC)
HPC is a fundamental pillar of modern science. From predicting weather to discovering drugs to finding new energy sources, researchers use large computing systems to simulate and predict our world. AI extends traditional HPC by allowing researchers to analyze large volumes of data for rapid insights where simulation alone cannot fully predict the real world.
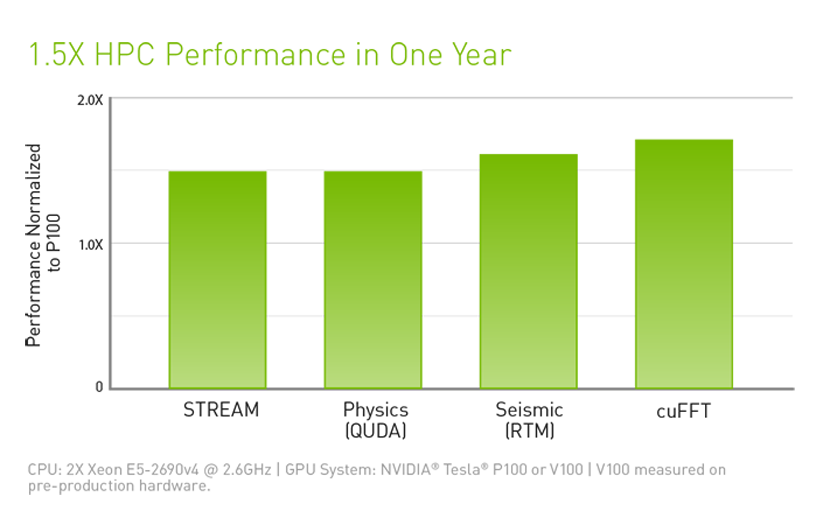
Tesla V100 is engineered for the convergence of AI and HPC. It offers a platform for HPC systems to excel at both computational science for scientific simulation and data science for finding insights in data. By pairing NVIDIA CUDA® cores and Tensor Cores within a unified architecture, a single server with Tesla V100 GPUs can replace hundreds of commodity CPU-only servers for both traditional HPC and AI workloads. Every researcher and engineer can now afford an AI supercomputer to tackle their most challenging work.
SPECIFICATIONS
|
|||||||||||||||||||||||||||||||||||||||||
SERVER |
NVIDIA PRODUCTS |
AI
|
MOTHERBOARDS
|
Beijin Sunway XinYue technology company lty
Tel:400-889-7783
|